What Does GPT-5 Mean for Contact-Center Tasks?
Authors: Ayush Kumar, Manager Machine Learning & Kawin M., Machine Learning Scientist
The highly anticipated arrival of GPT-5 has sparked both excitement and strategic reflection among technology teams in the contact center industry. Its appeal bolstered by public benchmark wins and impressive demonstrations in reasoning and coding is undeniable. Yet the operational reality of deploying it in a production-level contact center is far more intricate and demanding.
In this high-stakes setting, customer satisfaction depends on the seamless, precise orchestration of diverse Natural Language Understanding (NLU) capabilities, all operating under strict latency constraints. Within finely tuned pipelines, swapping a well-integrated model for the latest release is rarely straightforward. Such a change is a complex technical undertaking that, without thorough evaluation, can disrupt workflows. Strategically, it also carries the risk of undermining operational stability and diminishing the customer experience.
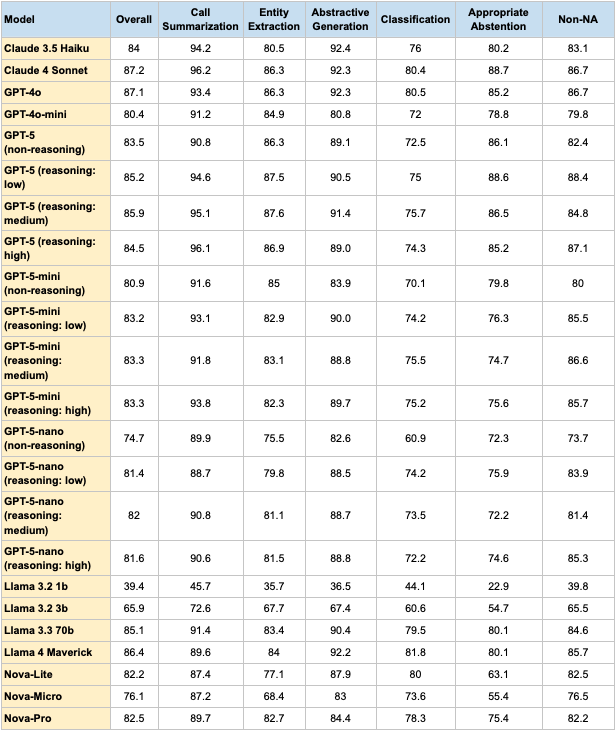
Our study benchmarks 17 distinct Large Language Models (LLMs) across six core contact center NLU task categories, paired with rigorous reasoning and latency analyses. The dataset comprises statistically robust, carefully curated examples that span simple to highly complex cases. The findings are clear: the optimal model choice is inherently task-specific. This challenges the assumption that the newest or largest model is always best. In several high-impact workflows critical to efficiency and customer satisfaction, smaller or faster models not only matched but often outperformed the latest, most advanced alternatives. These results highlight the importance of a nuanced, data-driven approach to model selection, one that prioritizes functional fit and measurable performance over broad perceptions of superiority.
Understanding the Task Categories
Each of the following task categories represents a critical capability in contact-center operations. While aggregated metrics are convenient for high-level comparison, they often mask nuanced trade-offs between accuracy, safety, and response time.
1. Call Summarization
This task evaluates a model’s ability to condense multi-turn conversations into concise, accurate summaries capturing the customer’s issue, the steps taken, and any resolutions or follow-ups. Effective summarization directly reduces agent after-call work, improves CRM data quality, and accelerates quality assurance processes.
- Top performers: Claude 4 Sonnet (96.2) and GPT-5 (reasoning: high) (96.1)
- Close contenders: GPT-5 (reasoning: medium) (95.1), GPT-5 (reasoning: low) (94.6) and Claude 3.5 Haiku (94.2).
The highest score is achieved by GPT-5 (reasoning: high) at 96.1, narrowly surpassing GPT-5 (medium) at 95.1 and GPT-5 (low) at 94.6. This task benefits disproportionately from higher reasoning settings in the flagship models, whereas in the mini and nano tiers, high reasoning does not yield a consistent advantage. For instance, GPT-5-mini (low) scores 93.1, slightly outperforming its high-reasoning counterpart (91.8, for GPT5-mini (medium)), and GPT-5-nano achieves its peak (90.8) at medium reasoning.
2. Entity Extraction
Entity extraction is the process of identifying structured data elements, such as names, policy numbers, transaction IDs, and dates from contact center interactions. This capability powers automation workflows, enabling accurate CRM updates, timely escalations, and efficient refund processing.
- Top performers: GPT-5 (reasoning: medium) (87.6) and GPT-5 (reasoning: low) (87.5)
- Close contenders: GPT-4o and Claude 4 Sonnet (both at 86.3).
Entity extraction scores are closely grouped, with GPT-5 (medium) leading at 87.6. Reasoning depth has minimal impact on performance; and in some cases, greater reasoning capability slightly reduces accuracy. Notably, GPT-5-mini remains competitive (82.3–85.0 range) despite its smaller parameter count, suggesting this task is less dependent on advanced reasoning.
3. Abstractive Generation
This category evaluates a model’s ability to follow an explicit instruction and produce coherent, fluent free-form text that satisfies specified content, style, and length constraints. Typical tasks include: drafting customer-facing responses from interaction context, and case narratives from cue points. Unlike extractive methods, abstractive generation requires synthesizing and reformulating information while strictly adhering to instructions and avoiding fabricated facts.
- Top performers: Claude 3.5 Haiku (92.4), GPT-4o (92.3), Claude 4 Sonnet (92.3) and Llama 4 Maverick (92.2)
- Close contenders: GPT-5 (reasoning: medium) (91.4).
Performance peaks at 91.4 for GPT-5 (medium), followed closely by GPT-5 (low) at 90.5. Interestingly, the high-reasoning setting underperforms slightly (89.0) compared with medium, suggesting that excessive reasoning depth may introduce verbosity or deviate from optimal stylistic targets. In the nano series, the low- and medium-reasoning settings (88.5–88.7) outperform the non-reasoning setting by a wide margin (+6 points), highlighting the benefit of modest reasoning in synthesis-heavy tasks.
4. Classification
This task measures whether a model can accurately assign labels or intents to an interaction. Examples include categorizing the reason for a call or identifying compliance-related metadata. Classification is often a key part of the call routing workflow, where errors can lead to misdirected cases and longer resolution times.
- Top performers: Llama 4 Maverick (81.8)
- Close contenders: GPT-4o (80.5), Claude 4 Sonnet (80.4).
Classification shows the narrowest spread in the flagship GPT-5 line, topping at 75.7 (medium reasoning) and bottoming at 72.5 (non-reasoning). Gains from higher reasoning are modest (≤3 points), and in the nano series, non-reasoning is notably poor (60.9), but jumps sharply with low reasoning (74.2), suggesting that a small model with no reasoning is insufficient for classification tasks.
5. Appropriate Abstention
This measures the model’s ability to recognize when it should refrain from answering, thereby avoiding hallucination or the fabrication of facts..
- Top performers: Claude 4 Sonnet (88.7), and GPT-5 (reasoning: low) (88.6).
- Close contenders: GPT-5 (reasoning: medium) (86.5)
The leader here is GPT-5 (low) at 88.6, with medium reasoning close behind (86.5). In the mini and nano series, abstention accuracy drops sharply, with scores in the low-to-mid 70s for most variants. This suggests abstention performance is more dependent on model capacity than on reasoning depth, and bigger models are likely better choices here.
6. Non-NA
This is the counterpart to abstention, evaluating whether the model provides the correct answer when information is indeed present.
- Top performers: GPT-5 (reasoning: low) (88.4).
- Close contenders: GPT-5 (reasoning: high) (87.1), Claude 4 Sonnet and GPT-4o (both at 86.7)
Top performance is achieved by GPT-5 (low) at 88.4, followed by GPT-5 (high) at 87.1. Medium reasoning underperforms slightly (84.8), despite being optimal in multiple other categories. Interestingly, in both mini and nano models, the best scores come from medium or low reasoning, while non-reasoning consistently lags, confirming that some reasoning depth is essential for high quality answers when the information is present.
7. Overall Score
The overall score consolidates performance across all task categories into a single figure.
- Top performers: Claude 4 Sonnet (87.2), GPT-4o (87.1).
- Close contenders: LLaMA-4 Maverick (86.4) and GPT-5 Reasoning (medium effort) at 85.9.
Across the GPT-5 family, overall scores range from 74.7 (GPT-5-nano, non-reasoning) to 85.9 (GPT-5, reasoning: medium). The flagship GPT-5 models consistently outperform their mini and nano counterparts, but the relationship between reasoning setting and overall score is non-linear, medium reasoning often surpasses both low and high settings, suggesting an optimal reasoning depth for aggregate performance.
Although this offers a quick comparative measure, it can obscure the compromises made in individual capabilities. Importantly, high overall performance did not translate into leadership in every individual task.
Reasoning Capability of GPT-5 Variants
When isolating reasoning as the primary differentiator, GPT-5’s performance scales consistently from its non-reasoning variant through low, medium, and high-reasoning modes.
- Non-Reasoning (Reasoning: Minimal): Optimized for speed and cost, this variant delivers strong baseline accuracy on straightforward tasks but shows noticeable drop-off on challenging cases, where shallow pattern-matching is insufficient.
- Reasoning: Low: Strikes a strong balance between reasoning depth and latency. It introduces structured intermediate reasoning steps, leading to a significant jump in accuracy over the non-reasoning variant, especially for GPT-5-nano a significant jump of 6.7% in quality.
- Reasoning: Medium: Achieves the best quality in most cases.
- Reasoning: High: Maximizes step-by-step deliberation, achieving the highest accuracy on tasks requiring synthesis, counterfactual reasoning, or constraint satisfaction. But on most tasks, results in regression of performance compared to medium reasoning effort.
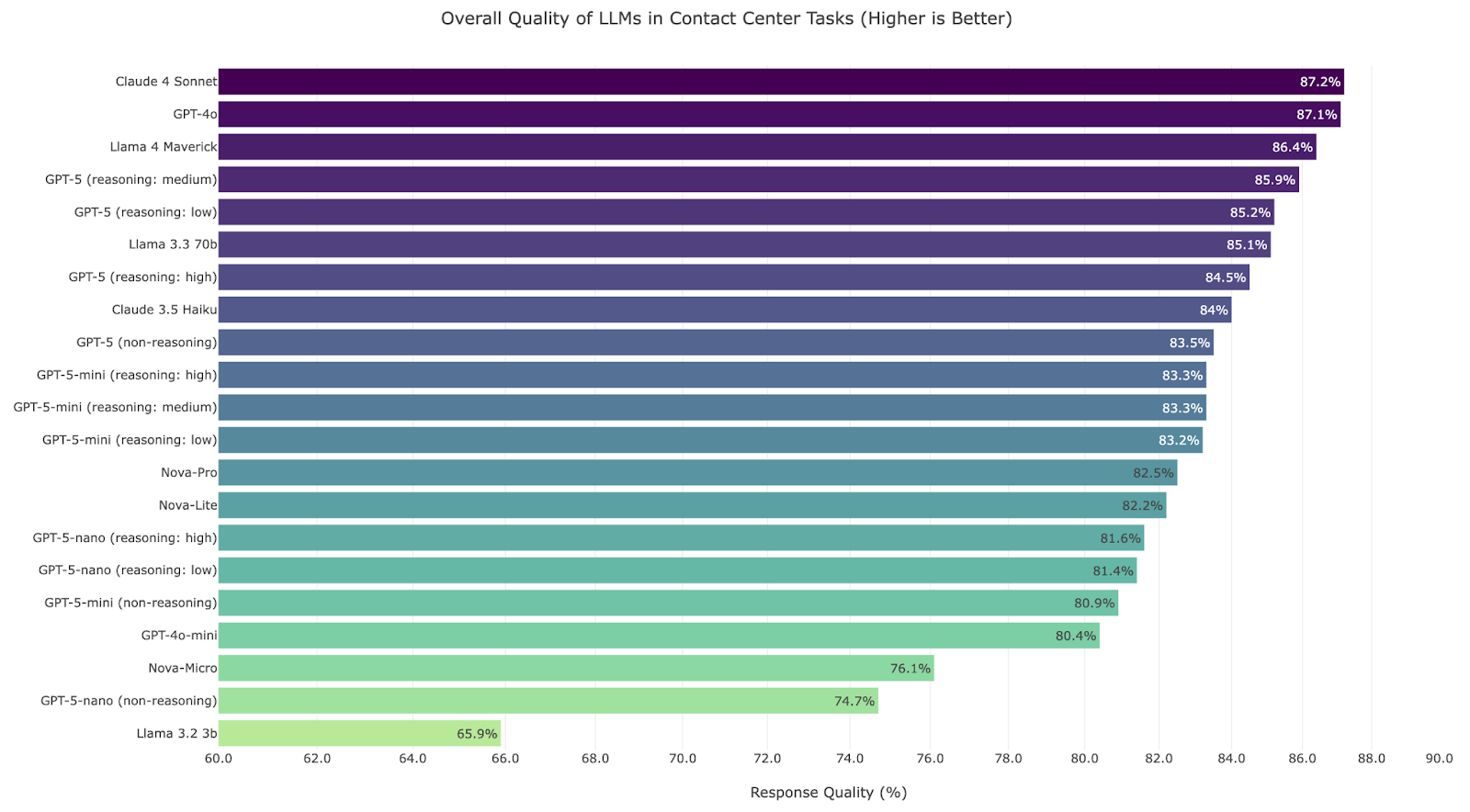
Reasoning and Output Efficiency of GPT-5 series LLMs
This analysis of GPT-5 series performance highlights a key trade-off between instructed reasoning effort and true cognitive efficiency. All GPT-5 models consistently produce more output than GPT-4o—between 1.39x and 1.84x more tokens—but efficiency is best measured by how quickly a model reaches conclusions with minimal articulated reasoning.
As the internal “reasoning effort” parameter increases from minimal to high for the same task, all models predictably become less efficient, generating more verbose reasoning tokens. At the minimal setting, GPT-5 models behave like non-reasoning LLMs: they are perfectly efficient, providing answers without reasoning overhead.
At the high-reasoning setting, a clear hierarchy emerges. GPT-5-mini is the most efficient reasoner, generating the fewest reasoning tokens relative to both its input (0.72) and its total output (33.07). This suggests its cognitive process is more integrated, requiring less explicit “show-your-work” articulation. GPT-5-nano is the least efficient, producing the highest ratio of reasoning tokens (1.04 and 59.43), indicating reliance on a more verbose, step-by-step approach when thinking deeply. The base GPT-5 model strikes a balance, offering a middle ground between the mini’s concise reasoning and the nano’s overt processing.
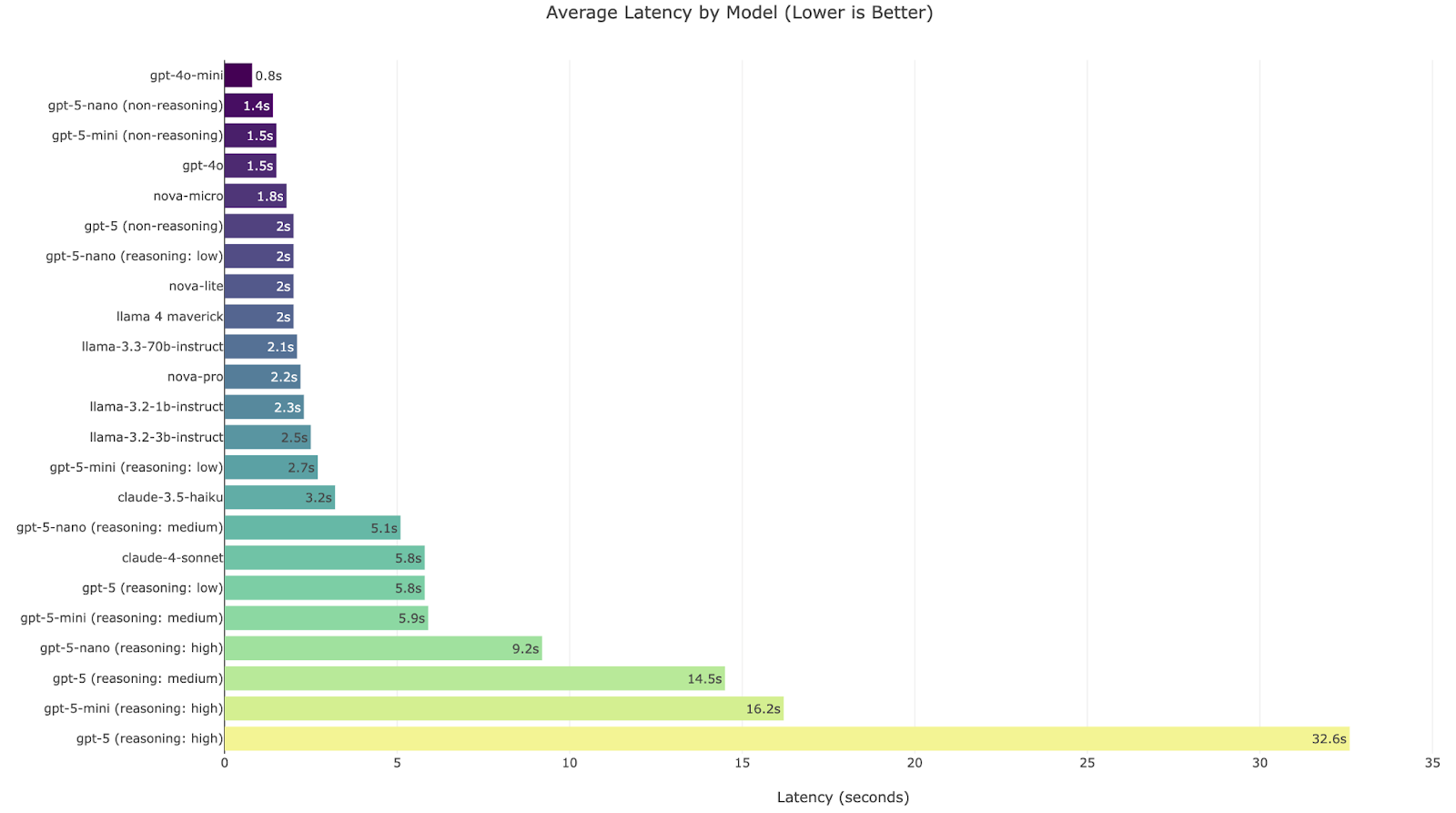
Latency Analysis: Speed matters as much as smarts
Our testing also revealed a massive spread in mean response times from 0.8 seconds for GPT-4o-mini to 32.6 seconds for GPT-5 (reasoning: high). In contact-center flows, those extra seconds can mean the difference between a smooth exchange and a frustrating pause.
In live interactions, speed is non-negotiable. A brilliant answer that takes six seconds to arrive can erode customer satisfaction and make agents less efficient. Our latency measurements showed a dramatic spread from 0.8 s for GPT-4o-mini to 32.6 seconds for GPT-5 (reasoning: high).
- Fast tier (<2 s): GPT-4o-mini, GPT-4o, Nova-Micro and GPT-5-nano, GPT-5-mini (both non-reasoning) — best for real-time tasks.
- Mid tier (2–3 s): GPT-5 (non-reasoning), GPT-5-nano (reasoning: low), nova-lite, nova-pro, Llama 3.2 1b, Llama 3.3 3b, Llama 3.3 70b, Llama 4 Maverick, GPT-5-mini (reasoning: low).
- Slow tier (>5 s): Claude 3.5 Haiku, Claude 4 Sonnet, GPT-5 series with reasoning enabled.
Why “just switch to GPT-5” can backfire
The results tell a nuanced story. While GPT-5 and its reasoning variants score highly in several categories—particularly in abstractive and entity tasks—they are not universally best. Claude 4 Sonnet, GPT-4o, and other contenders outperform them in certain classification and default-prompt scenarios. Latency is another decisive factor. Our measurements ranged from just 0.8 seconds for GPT-4o-mini to 32.6 seconds for GPT-5 (reasoning: high). In contact-center settings, that gap can mean the difference between a smooth, natural conversation and an interaction marred by awkward pauses. Fast, smaller models like GPT-4o-mini or GPT-5-nano can match or nearly match the accuracy of larger models in routing and simple extraction tasks, all while delivering sub-two-second responses.
These findings highlight a key principle: public benchmark superiority does not guarantee domain superiority. A model tuned for generic tasks may stumble on your specific refund workflow or compliance macro. Prompts that worked flawlessly on an older model can degrade or unexpectedly improve on a newer one, a phenomenon known as non-monotonic performance. And even when accuracy rises, a jump in latency from two seconds to six can erode customer satisfaction and deflection rates.
This data underscores that public benchmark leadership doesn’t guarantee domain superiority. GPT-5 shines in certain tasks, but other models outperform it elsewhere, sometimes at a fraction of the latency. Prompts tuned for GPT-4o may regress on GPT-5 and vice versa, a phenomenon known as non-monotonic performance. And in contact centers, latency is not a technical afterthought, it’s a customer experience feature. Moving from two seconds to six can drop customer satisfaction and deflection rates even if accuracy improves.
We also found that GPT-5's reasoning mode is impressive, but only if we use GPT-5. Based on our initial observations, GPT-5 does reasoning efficiently, it takes <500 tokens for simple to medium complex tasks. But for the same tasks, the nano variant, especially, was using >5000 tokens just to reach a similar answer. It’s inefficient and gives the impression of unnecessary mental gymnastics
The smarter path: evaluate, route, and adapt
GPT-5 is a powerful addition to the contact-center LLM toolkit—but it’s not a universal upgrade button. The real advantage will go to teams that evaluate responsibly, understand the trade-offs between speed and accuracy, and route intelligently based on task demands. In a world where customer experience can hinge on both the quality and speed of an answer, the smartest move is not to switch fast—it’s to switch wisely.
Rather than aiming for one-click model switching, contact centers should build a task-aware evaluation and routing strategy. That means:
- Defining performance and latency budgets for each task type.
- Building domain-specific evaluation sets with both NA and Non-NA examples.
- Measuring cost per successful outcome, not just accuracy.
- Treating prompts like code, versioned, tested, and pinned to model IDs.
- Routing queries: default to fast, capable models for most turns; escalate to GPT-5 or GPT-5 Reasoning only for complex, high-risk, or policy-ambiguous cases.
Subscribe to our newsletter.
Frequently Answered Questions

.png)



.png)
.png)