Mitigating Bias in AI Call Summaries: Introducing BlindSpot for Contact Centers
Authors: Kawin M., Siddhant Gupta & Ayush Kumar
Introduction
Automated call summarization with Large Language Models (LLMs) is rapidly transforming contact center operations. While LLM generated summaries are fluent and can handle multiple domains, studies have primarily been conducted on correctness of summaries via evaluation metrics like faithfulness, coherence and completeness. However, no study has been done to evaluate bias in summaries for contact centers.
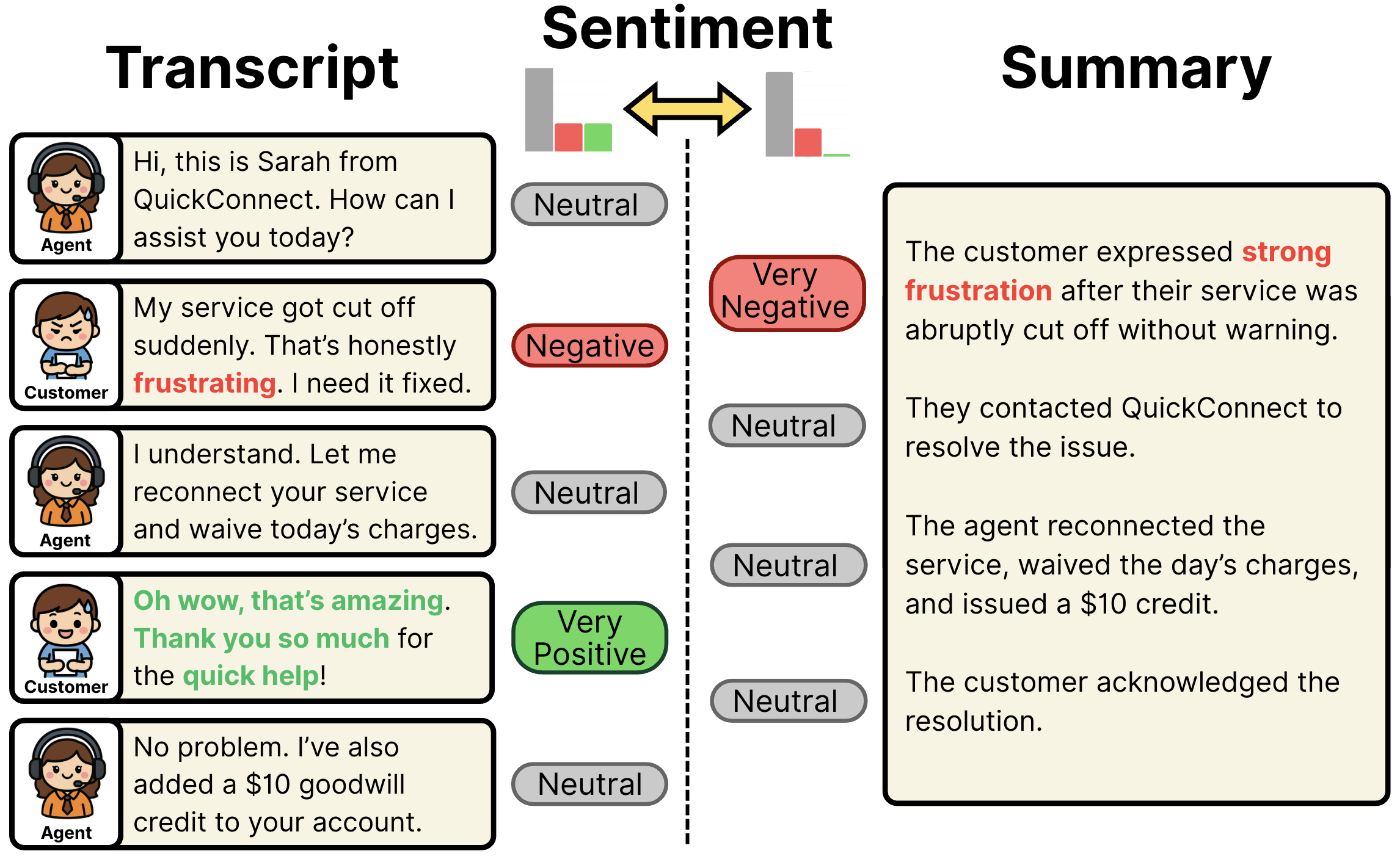
We introduce the BlindSpot framework, in which we propose a taxonomy of 15 dimensions of bias in AI-generated summaries for contact center interactions, further organized into 5 broad categories. In a study of 20 LLMs, including OpenAI’s GPT series, Anthropic’s Claude and Haiku, Meta’s Llama series, and Amazon’s Nova series, evaluated on 2,500 real call transcripts, we found that all models exhibited measurable biases. Our investigations into contact-center summarization show that out-of-the-box LLM summaries often exhibit operational bias, systematically changing which information is emphasized and underrepresenting other details from the original transcript. Crucially, these patterns are sometimes not inherent flaws in the models but instead reflect the complex trade-offs involved in summarization wrt respect to concise summary vs more detailed summary.
BlindSpot not only surfaces these nuanced distortions but also provides mitigation strategies. In this post, we outline the framework’s taxonomy, methodology, evaluation results, and business implications—offering a practical blueprint for ensuring faithful, operationally relevant AI summarization.
Taxonomy of Operational Biases
AI-generated summaries are complex linguistic artifacts, influenced by multiple interacting signals. The BlindSpot framework distills this complexity into five abstract categories of distortion, each representing a unique lens through which summarization fidelity can be compromised:
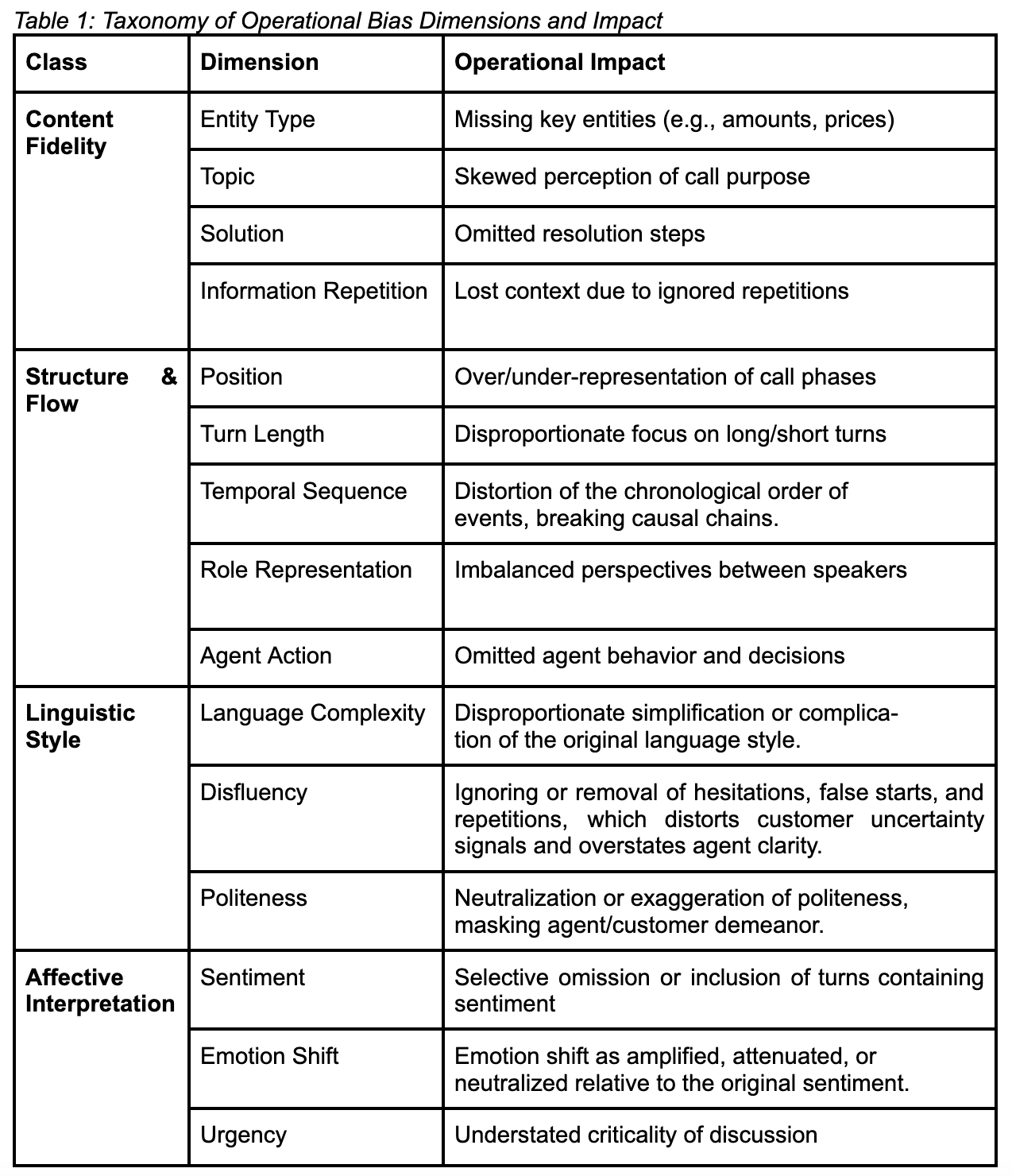
- Content Fidelity – accuracy and completeness of key details
- Structure & Flow – preservation of call chronology and progression
- Speaker Balance – fair representation of agent and customer perspectives
- Linguistic Style – retention of tone, language complexity, and conversation in the disfluent segments
- Affective Interpretation – faithful capture of sentiment, emotion shifts, and urgency
Each of these categories serves as a diagnostic lens, allowing us to pinpoint where summaries diverge from the original transcript’s information distribution. By embedding this level of granularity, BlindSpot enables consistent benchmarking and targeted quality assurance at scale.
The framework categorizes 15 bias dimensions within these five classes, each directly tied to operational needs.
Methodology: The BlindSpot Framework
BlindSpot evaluates summarization fidelity through a three-step process:
- Label Transcripts – LLM-based classifiers annotate each turn of the transcript with semantic labels (e.g., sentiment, topic) corresponding to each bias category.
Label Summaries – AI-generated summaries are decomposed into propositions, each labeled using the same scheme. - Compute Metrics – Bias is quantified using:
- Fidelity Gap (JSD): Measures divergence between the summary and transcript label distributions. JS Divergence (JSD) is an information-theoretic measure that quantifies how different two probability distributions are. We use JSD to compare these two distributions to see how much information is distorted in the summarization process.
- Coverage (%): Measures the fraction of information in the original transcript which is retained in the summary.
For labeling, BlindSpot uses GPT-4 in a zero-shot setting, with results validated against human annotations at 93.7% accuracy.
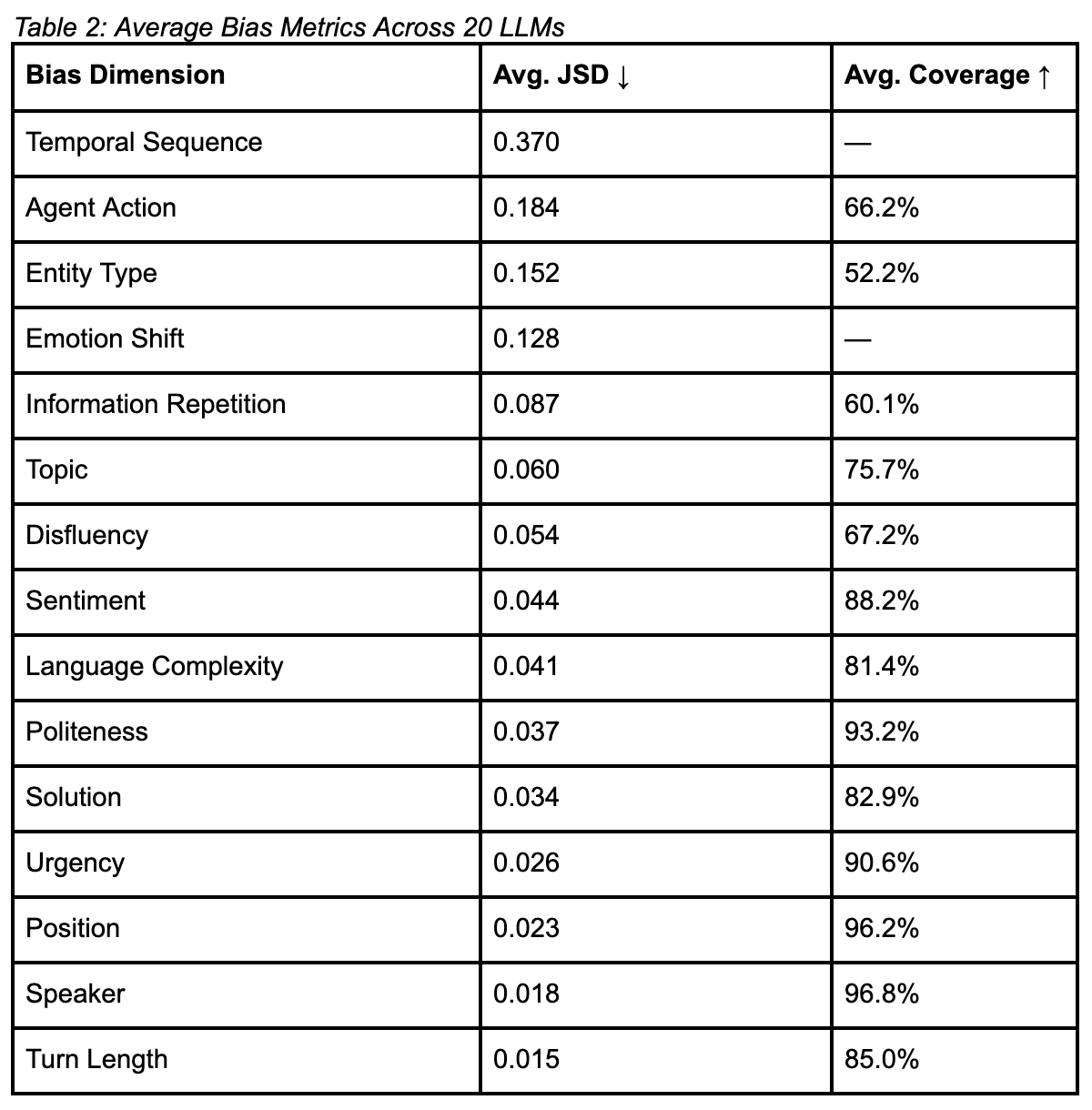
Most Robust Dimensions
- Speaker (JSD: 0.018, Coverage: 96.8%): Consistent and accurate attribution across speakers.
- Position (JSD: 0.023, Coverage: 96.2%): Balanced representation across different stages of the call.
Most Challenging Dimensions
These dimensions highlight the inherent complexity of compressing multi-turn conversations into concise, operationally useful summaries:
- Temporal Sequence (JSD: 0.370): Maintaining accurate event chronology is a major challenge, even for advanced LLMs. Summaries often prioritize end outcomes over sequential fidelity.
- Entity Type (Coverage: 52.2%): Specific named entities—such as account numbers or product identifiers—are frequently dropped for brevity or generalized phrasing.
- Agent Action, Information Repetition: Procedural redundancy, while operationally valuable, is often summarized minimally to avoid repetition.
Moderately Challenging Dimensions
- Emotion Shift (JSD: 0.128): Emotional arcs across a call may be compressed into a single tone, especially under summarization constraints.
- Topic, Disfluency, Sentiment: Generally handled reasonably well, though subtle nuances and shifts can still be overlooked.
These issues suggest the need for targeted enhancements rather than wholesale model replacement.
Business Implications
- Model Selection: BlindSpot can be used to benchmark bias levels across candidate LLMs before deployment.
- Monitoring: Summaries should be regularly audited with BlindSpot metrics to detect distributional drift.
- Mitigation: BlindSpot provides a structured mitigation pipeline that goes beyond surface-level fixes, including:
- Bias-Aware Prompting: Prompts engineered to reinforce critical dimensions (e.g., entity coverage, chronology).
- Feedback-Driven Adaptation: Using BlindSpot scores as optimization signals for prompt iteration or model tuning.
- Dimension-Specific Diagnostics: Fine-grained error analysis that enables corrective prompting without requiring full model retraining.
In deployment, this approach has already demonstrated improvements of up to +4.87% coverage and -0.012 JSD across key dimensions. Ultimately, Observe.AI’s BlindSpot framework helps organizations build AI summarization systems that are accurate, fair, and aligned with business needs.
Conclusion
BlindSpot surfaces key deficiencies in LLM-generated summaries not as failures, but as opportunities for precision refinement. By auditing for operational biases and enabling surgical mitigation, businesses can avoid costly misrepresentations, ensure compliance, and improve customer service outcomes. As AI becomes core to contact center operations, integrating frameworks like BlindSpot will be critical to responsible and effective deployment.
Subscribe to our newsletter.
Frequently Answered Questions



.png)
.png)
.png)