How Observe.AI improves transcription accuracy for rare, domain-specific and out-of-vocabulary terms
What is an out-of-vocabulary term?
An out-of-vocabulary (OOV) term is a word that an Automatic Speech Recognition (ASR) model has not encountered in its training data. Because these words are not part of the model's predefined vocabulary, the system cannot recognize or properly process them, leading to errors.
OOV words are a significant challenge for businesses who operate contact centers with large call volumes. They are often:
- Proper nouns: Names of people, places, or brands.
- Domain-specific terms: Technical terms in fields like healthcare or finance.
- New or evolving language: Newly introduced terms such as policy names, or acronyms that weren't prevalent when the model was trained.
The High Cost of missed OOV terms
Conversation transcripts are the currency of a contact center, where precision is paramount. When Out-of-Vocabulary (OOV) words are missed, the transcript error cascades downstream, creating significant problems that can multiply within the contact center. Let’s take a closer look at some of these risks:
Critical Risk and Compliance Gaps: In regulated industries, an inaccurate transcript is not a typo, it's a liability. Misidentified names of products, policies, or disclosures are unauditable and non-compliant. For example, a retail bank, with inaccurate loan type, can create a significant compliance risk.
Business Intelligence Blind Spot: Inaccurate transcripts lead to flawed analytics. If you can't reliably analyze or search through the goldmine of conversation data you can't find patterns or perform root-cause analysis. For example, a hospital system tries to analyze call drivers for a specific location. If the ASR mis-transcribes the name, all those high-value interactions get lost in general call data.
Sabotages AI-reliant outcomes: A single transcript error can potentially undermine the effectiveness of the contact center’s AI and data ecosystem. An AI Agent might misinterpret the customer’s intent, an AI Copilot (Agent assist) might not provide the right guidance during a call, and it can compromise AI-driven evaluations of performance
Solving the OOV problem is not just a technical challenge; it's a foundational requirement for mitigating risk, controlling costs, and making data-driven strategic decisions.
Drawbacks of current methods
While modern LLMs are incredibly accurate with everyday language, their performance plummets when trying to recognize rare, domain-specific, and Out-of-Vocabulary (OOV) This effect amplifies within noisy, chaotic contact center environments.
Conventional methods to fix this, known as context biasing, & shallow fusion, for example, work by trying to boost the probability of words from the bias list during the final decoding step. Other methods using Weighted Finite-State Transducers (WFSTs) embed the new vocabulary directly into the ASR’s core search grammar.
However, both approaches become ineffective or computationally expensive as the biasing list grows large, a common scenario for any enterprise with an extensive product or service catalog. The alternative, fully retraining the entire ASR model for every new term, is simply too slow and expensive to be a practical solution for a dynamic business.
Our Solution: The Spot and Merge (SAM) System
Conventional methods for handling out-of-vocabulary (OOV) terms just don’t cut it. Shallow fusion and WFSTs buckle under the pressure of the large, dynamic vocabularies. Fully retraining the entire ASR model for every new product or brand name is simply too slow and expensive to be practical.
That’s why our Spot and Merge (SAM) system is designed to be both surgically precise and highly efficient, creating a new path forward without compromise. SAM integrates the strengths of shallow fusion and deep context biasing, with the following contributions:
- A Low-Rank Adapter (LoRA)–based module that integrates with the ASR model.
- A mechanism that spots biased words by examining cross-attention weights across the LoRA module.
- A merge strategy, which dynamically injects recognized bias words into the decoding output stream.
This design enables the base ASR model to remain largely unchanged while effectively recognizing rare/OOV terms—even with extensive biasing lists—without requiring full joint retraining.

The Secret Sauce: How 'Phrase Spot Loss' Improves Accuracy
To increase the accuracy and have better convergence we introduced a technique called Phrase Spot loss. The purpose of this method is to focus attention only on bias phrases present in the utterance, reduce false attention on absent phrases, improve discrimination between relevant and irrelevant phrases, and provide an auxiliary supervision signal to stabilize cross-attention learning. It works through the following components:
- Presence vector (K): A binary indicator marking which bias phrases are present in the input.
- Spotting probability (P): Computed by summing attention weights for each phrase across time and applying a tanh function to normalize values into the range [0, 1].
- Phrase-level calibration: Encourages the attention distribution to align with the actual presence of phrases.
This design ensures more reliable bias phrase spotting and better overall alignment of contextual information during decoding.
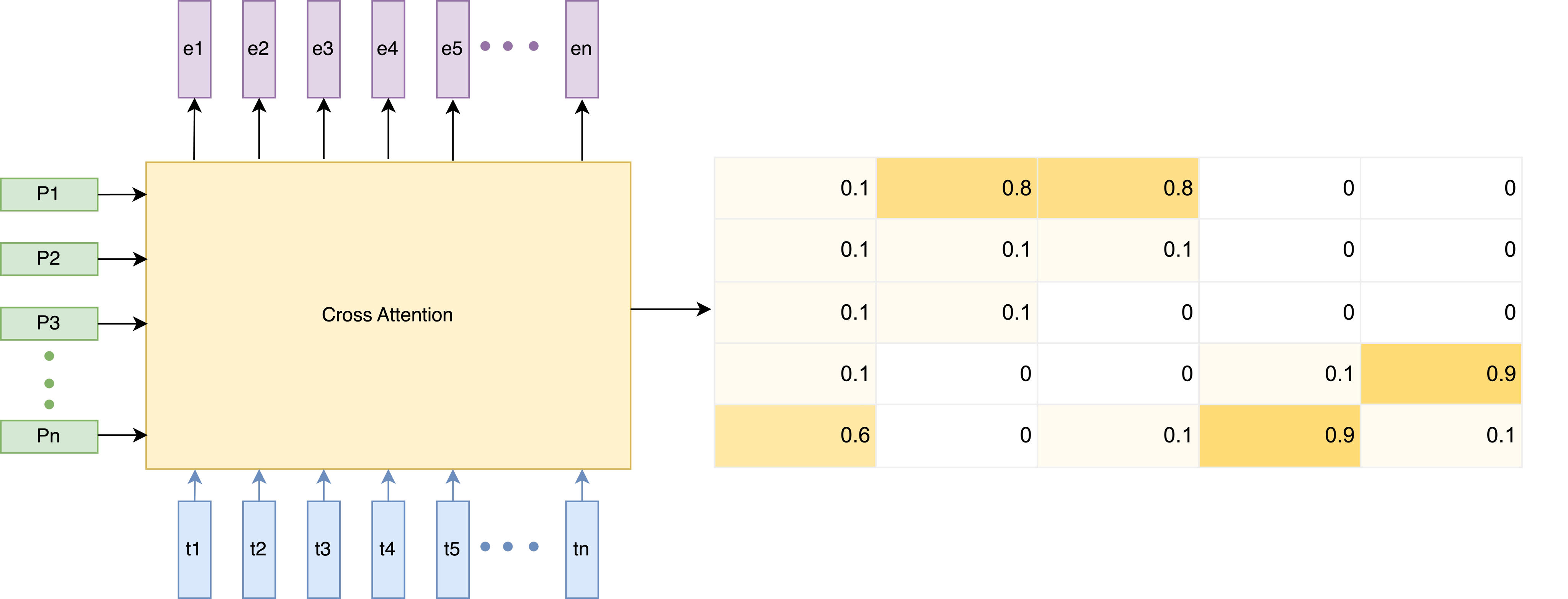
Under the Hood: The Two-Step Spot & Merge Algorithm
So, how does the Spot and Merge algorithm work? The process is broken down into two distinct, sequential phases: a "Spotting" phase and a "Merging" phase
Spotting Phase
Spotting Phase accurately detects which pre-defined bias phrases are present in the raw audio before the final transcription is generated.
- It Uses cross-attention weights from the biasing module (with LoRA adapters).
- Then it identifies which bias phrases in the list are likely present in the input speech.
- Finally it generates a presence vector marking the spotted phrases.
Merging Phase
The Merging Phase intelligently integrates spotted phrases into the final text, ensuring the output is contextually and grammatically correct.
- During decoding, merges the spotted phrases into the recognition output
- Ensures bias phrases appear only where relevant, avoiding false insertions.
- Helps resolve ambiguity at word boundaries (avoiding repetitions or deletions).
- Makes biasing both accurate and selective: it boosts recognition of rare/OOV words while reducing noise from irrelevant bias terms.
From Error to Insight: The transformative Impact of OOV Accuracy
Handling brand and product names is critical for downstream analysis, but more importantly, for maintaining customer experience and brand perception. Here’s how Observe.AI’s OOV mechanism mitigated high-stakes issues in the real-world
- A large food delivery platform struggled with operational blind spots as their ASR misinterpreted menu items, making it impossible to analyze complaint data. Once transcription was corrected, they could isolate which items from which partners caused service issues, enabling targeted quality improvements.
- A major BPO found that ASR errors on their clients' brand names were eroding trust during calls. Correcting these transcriptions wasn't just about data accuracy; it was about respecting their clients' brands, which strengthened business relationships and proved their commitment to quality.
Putting SAM to the Test: The Results
- Scales to Large Bias Lists – Maintains recognition quality even as bias lists grow; achieves 1.5% absolute WER reduction over strong contextual adapter baselines.
- Improved OOV Recognition – On proprietary contact-center data, boosts rare and domain-specific word detection with 73% absolute F1.
- Benchmark Validation – On LibriSpeech, delivers a 1.0% absolute WER reduction, showing general applicability beyond specialized domains.
Efficient Adaptation – Uses LoRA adapters with spot-and-merge logic, enabling effective biasing without full model retraining.
Subscribe to our newsletter.
Frequently Answered Questions



.png)
.png)
.png)