

Problem Statement
Modern end-to-end (E2E) Automatic Speech Recognition (ASR) systems have achieved impressive accuracy on general speech. Yet they still struggle with rare and out-of-vocabulary (OOV) words, especially in contact-center environments, where brand names, product names, and domain-specific terminology frequently appear. Conventional context biasing methods, like shallow fusion or weighted finite-state transducers offer some mitigation, but often fail when the biasing list grows large. Retraining models to incorporate these words isn't always practical.
Proposed Approach: Spot and Merge (SAM)
To address these limitations, we propose a system that integrates the strengths of shallow fusion and deep context biasing, with the following contributions:
- A Low-Rank Adapter (LoRA)–based module that integrates with the ASR model.
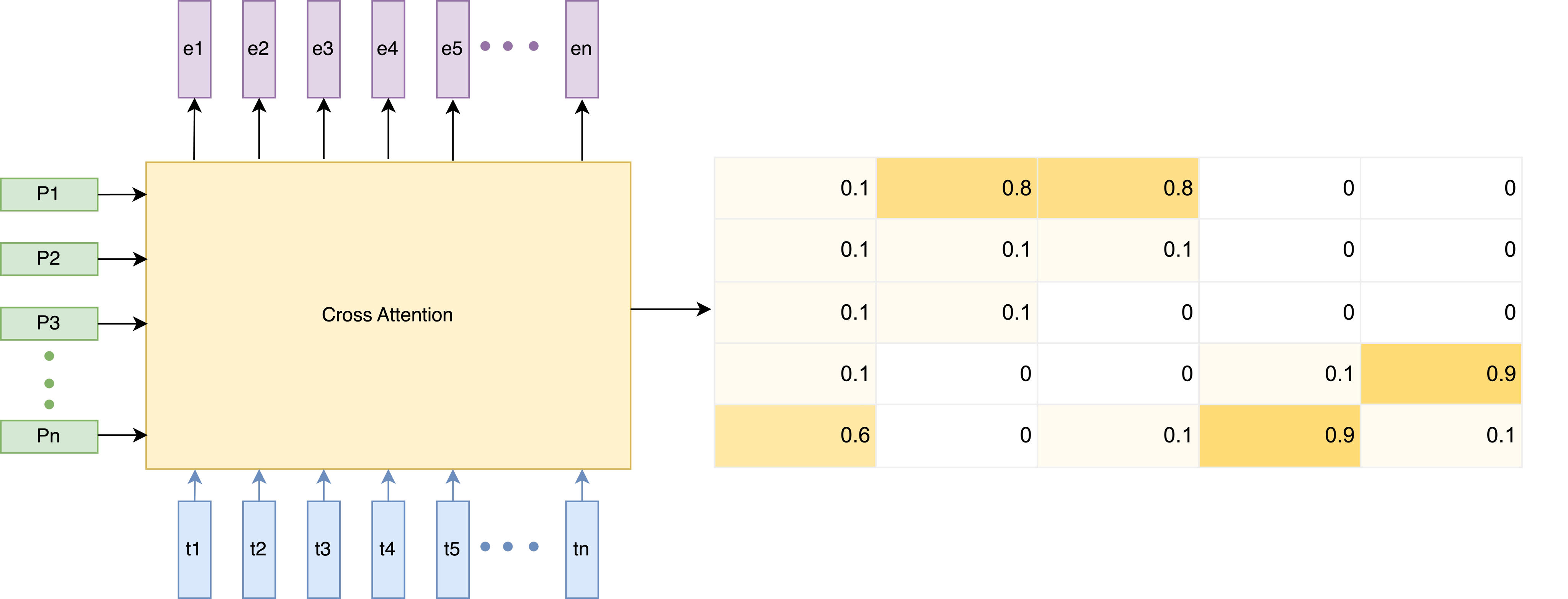
- A mechanism that spots biased words by examining cross-attention weights across the LoRA module.
- A merge strategy, which dynamically injects recognized bias words into the decoding output stream.
This design enables the base ASR model to remain largely unchanged while effectively recognizing rare/OOV terms—even with extensive biasing lists—without requiring full joint retraining.

Phrase Spot Loss :
To increase the accuracy and have better convergence we introduce Phrase Spot loss. The purpose of this method is to focus attention only on bias phrases present in the utterance, reduce false attention on absent phrases, improve discrimination between relevant and irrelevant phrases, and provide an auxiliary supervision signal to stabilize cross-attention learning. It works through the following components:
- Presence vector (K): A binary indicator marking which bias phrases are present in the input.
- Spotting probability (P): Computed by summing attention weights for each phrase across time and applying a tanh function to normalize values into the range [0, 1].
- Phrase-level calibration: Encourages the attention distribution to align with the actual presence of phrases.
This design ensures more reliable bias phrase spotting and better overall alignment of contextual information during decoding.
Spot & Merge Algorithm :
Spotting Phase
- Uses cross-attention weights from the biasing module (with LoRA adapters).
- Identifies which bias phrases in the list are likely present in the input speech.
- Generates a presence vector marking the spotted phrases.
Merging Phase
- During decoding, merges the spotted phrases into the recognition output
- Ensures bias phrases appear only where relevant, avoiding false insertions.
- Helps resolve ambiguity at word boundaries (avoiding repetitions or deletions).
- Makes biasing both accurate and selective: it boosts recognition of rare/OOV words while reducing noise from irrelevant bias terms.
Results
- Scales to Large Bias Lists – Maintains recognition quality even as bias lists grow; achieves 1.5% absolute WER reduction over strong contextual adapter baselines.
- Improved OOV Recognition – On proprietary contact-center data, boosts rare and domain-specific word detection with 73% absolute F1.
- Benchmark Validation – On LibriSpeech, delivers a 1.0% absolute WER reduction, showing general applicability beyond specialized domains.
- Efficient Adaptation – Uses LoRA adapters with spot-and-merge logic, enabling effective biasing without full model retraining.

















