How Observe.ai Migrated 1.8 Billion Documents with High Throughput and Zero Downtime
Introduction: Legacy Challenges and Motivation
At Observe.AI , we recently embarked on a large-scale data migration, moving 1.8 billion interaction documents from our legacy MongoDB v0 datastore to a newly architected stack comprising MongoDB v1, Amazon S3, and Snowflake.
These interaction documents - which include call metadata, criteria, and signal evidence - had significantly outgrown their original schema and storage design. Over time, the v0 collection had ballooned to 9.98TB, burdened by deeply nested structures and oversized JSON payloads accumulated across years of data. This resulted in severe performance degradation, inefficient indexing, and escalating operational overhead. The cluster’s fragile state made even routine optimizations like reindexing risky, necessitating an immediate and strategic overhaul.
While sharding was initially explored to improve stability, the sheer volume of data made that approach complex, expensive (estimated at 1.5x infrastructure cost), and operationally risky (as suggested by Mongo team) - prompting us to pursue a more holistic and future-proof migration strategy.
Why Migrate?
We needed a scalable, analytics-friendly architecture that could keep up with growing data volumes and evolving product needs. Our new design aimed to refactor both storage and access patterns:
- MongoDB v1 became the new operational store, redesigned with a leaner schema to support faster reads and writes.
- Amazon S3 was introduced to offload heavy, unstructured content (such as metadata and transcripts), reducing database bloat and enabling long-term, cost-efficient storage.
- Snowflake was integrated as the central analytical warehouse, enabling powerful historical reporting, ML pipelines, and cross-platform insights.
This migration needed to be executed with zero disruption to live traffic and with strict consistency guarantees across all three systems - MongoDB v1, S3 and Snowflake.
In this blog, we’ll take you through how we pulled off a migration of this scale:
- Milestone-Based Rollout Strategy
- Broke 1.8B records into manageable, verifiable chunks,
- Parallelized the entire process across threads and pods for high throughput,
- Tuned our pipeline to double ingestion speed (from ~3K to ~6K docs/sec),
- Integrated with Kafka and Snowflake to keep all systems in sync during the migration.
Milestone-Based Rollout Strategy
To ensure a safe and seamless transition from our legacy infrastructure to the new architecture, we adopted a milestone-based migration approach. This allowed us to progressively enable features, test at scale, and shift traffic with minimal risk- while keeping both _v0 and _v1 systems in sync.
Current State: Legacy Stack (_v0)
Initially, the backend wrote interaction data to the interactions_v0 collection, which was then streamed to Snowflake via Hevo_v0.
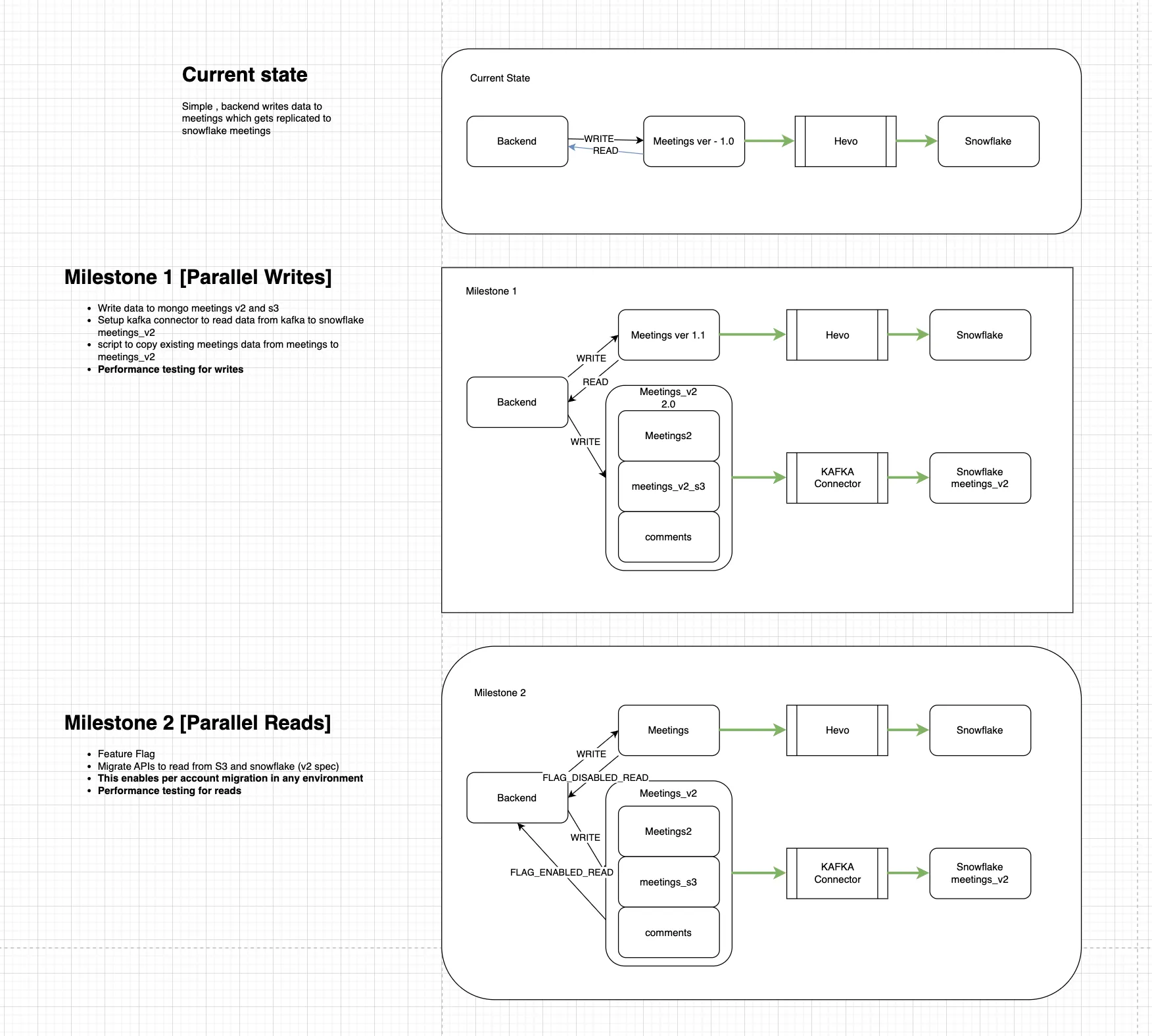
Milestone 1: Parallel Writes
- ✅ Dual Writes Enabled: Backend services began writing in parallel to both:
- interactions_v0 (legacy)
- interactions_v1, consisting of:
- interactions_v1
- interactions_s3_v1 (for heavy field offload)
- comments_v1
- v1 Infra Setup: Setting up the new infra - mongodb, S3, kafka topic, kafka connector, snowflake stage, streams, tasks, stored procedure.
- Historical Migration: Migrate historical data from interactions_v0 into the new interactions_v1 stack to synchronize the data between the legacy and new systems.
- Write Performance Validation: Ensured that the dual-write setup could handle scale without affecting latency or system load.
Milestone 1 concludes when dual writes are fully operational and the historical backfill to the _v1 infrastructure is complete. At this stage, both _v0 and _v1 systems remain in a consistent state, ensuring parity across storage and downstream pipelines.
Milestone 2: Parallel Reads
- Feature Flags Introduced: Read paths were controlled via feature flags:
- If disabled, reads were served from interactions_v0.
- When enabled, reads switched to the new interactions_v1 stack.
- Per-Tenant Migration Support: Allowed tenant-wise cutover to interactions_v1 in any environment.
- Read Performance Testing: Validated correctness and performance of reads from the new schema before a full cutover.
Milestone 2 concludes when all reads are successfully redirected to the _v1 infrastructure, ensuring complete reliance on the new data paths for retrieval.
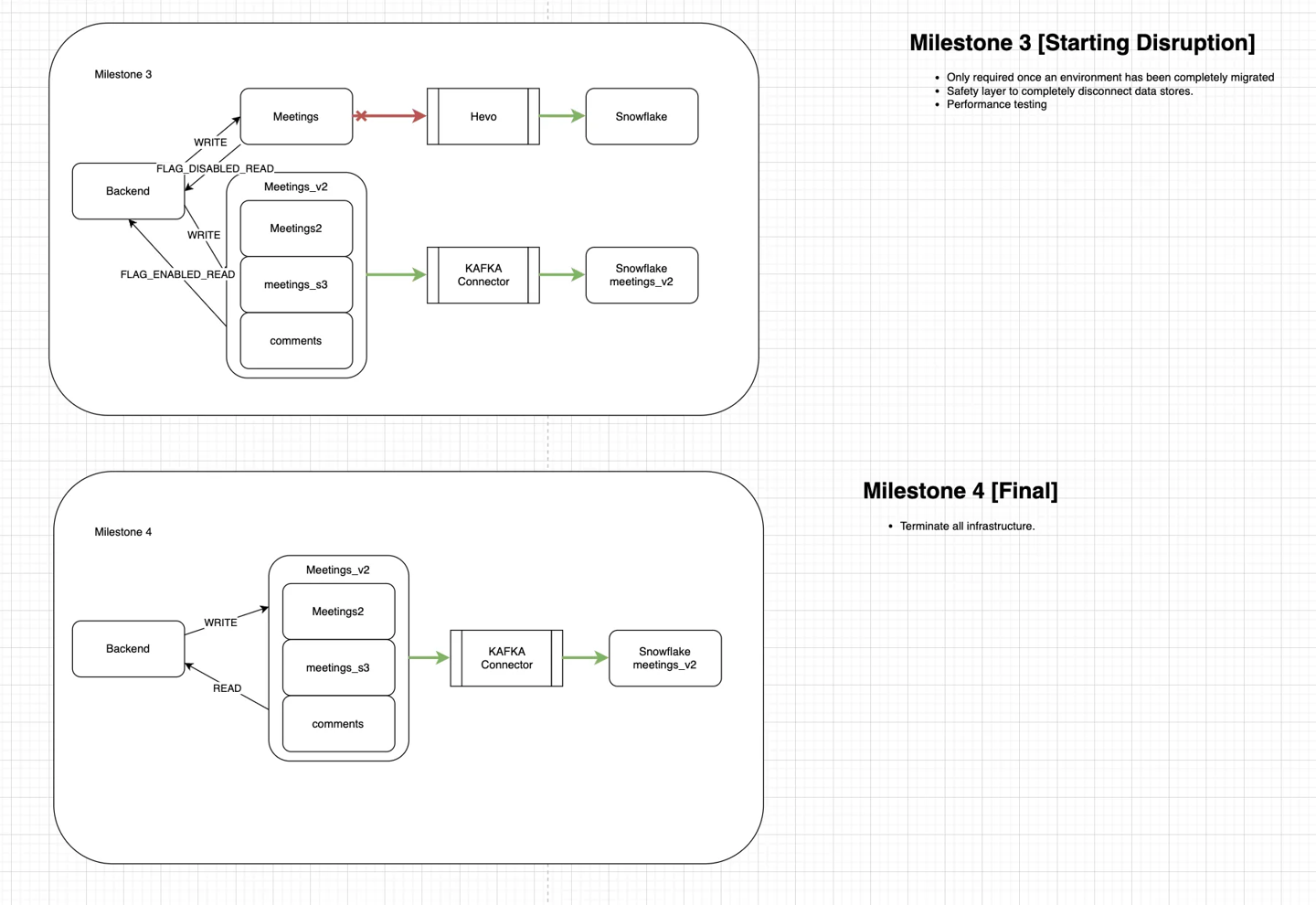
Milestone 3: Controlled Cutover (Start of Disruption)
- Write Shutdown to interactions_v0: All writes to the legacy system were disabled.
- Full Write/Read on interactions_v1:
- Backend continued dual writes until confirmed safe to stop.
- Reads were now served entirely from interactions_v1.
- Safety Layer Maintained: The interactions_v0 stack remained in place temporarily for rollback safety and additional verification.
Milestone 3 concludes when writes to the _v0 infrastructure are fully disabled, marking the end of any data dependency on the legacy system.
Milestone 4: Final State
- Legacy Infrastructure Decommissioned:
- interactions_v0 and Hevo_v0 pipelines were shut down.
- All traffic routed through interactions_v1, including:
- Writes to interactions2_v1, interactions_s3_v1, and comments_v1
- Kafka streaming to Snowflake_interactions_v1
- New Architecture Activated as Source of Truth
Milestone 4 concludes with the complete decommissioning of the _v0 infrastructure, officially closing the migration effort and solidifying _v1 as the single source of truth.
This milestone-driven execution helped us phase out legacy dependencies while maintaining data consistency, high availability, and operational visibility throughout the migration. Each milestone acted as a gated checkpoint to validate stability before moving to the next phase.
Migration Strategy Overview
Migrating billions of records presented substantial challenges in scale and complexity. To handle this efficiently and reliably, we adopted a divide-and-conquer approach, segmenting data logically based on tenants and time ranges, enabling parallel processing.
At a high level, each migration task involved:
- Extract: Retrieve interaction documents from
MongoDB_v0for a specific tenant and day range. - Transform: Modify and enrich documents to fit the new schema, including adding metadata such as S3 storage paths and pruning or separating certain large sub-fields.
- Load to S3: Store full JSON payloads in Amazon S3, using structured and unique paths for efficient, long-term storage.
- Load to MongoDB_v1: Bulk-insert transformed documents (pruned data) into the new MongoDB cluster, referencing S3 paths.
- Publish to Kafka: Stream documents via Kafka, facilitating real-time ingestion into Snowflake through the Kafka-Snowflake connector.
- Verify: Confirm successful completion of each chunk by comparing record counts and marking the task as complete.
To orchestrate and monitor these steps effectively, we wrote the migration script that executes the entire steps mentioned above inside our existing service that runs by giving specific the parameter as run_mode = migration to the JVM. We utilised K8s Job to start up the migration pods, ensuring that the deployment of these pods was managed effectively and could be scaled as needed.
Next, let's explore the critical design decisions underpinning this strategy.
Partitioning Migration Tasks by Tenant and Day
Effective partitioning was vital to the manageability and robustness of the migration. We introduced a dedicated MongoDB collection named arcaneMigrationRequests(Our project named being Arcane) to serve as our task queue, with each document representing a discrete unit of migration work - data for one tenant over a single day.
Each MigrationRequest document included:
tenantId: Identifier for the tenantstartTimeandendTime: Time boundaries of the day-rangeexpectedInteractionsCount: The count of interaction records in v0status: Current processing state (PENDING(default state),STARTED,COMPLETED,FAILED,MISMATCH)migratedInteractionsCount: The actual number of records migrated, updated post-processing- Timestamps for tracking and auditing purposes
All migration tasks began in a PENDING state, transitioning through statuses atomically as processing progressed. This structure provided clear visibility into migration progress and facilitated easy verification and troubleshooting.
Why Day-wise Partitioning?
Breaking migration into daily chunks offered several advantages:
- Manageable Task Sizes: Each day's data volume was moderate (typically thousands to half a million of records), simplifying operational handling.
- Easier Verification: Day-level granularity made record counts straightforward to verify and discrepancies easy to isolate.
- Efficient Error Handling: Issues encountered on specific days required only targeted reprocessing, avoiding unnecessary work.
Task Generation and Idempotency
We automated task generation by iterating over all tenants to determine the relevant date ranges:
for each tenantId in allTenants:
earliestTime = findFirstRecordTime(tenantId, v0);
latestTime = findLastRecordTime(tenantId, v0);
if (earliestTime == null) continue;
dayRanges = splitIntoDayRanges(earliestTime, latestTime);
for each dayRange in dayRanges:
count = v0.count(tenantId, dayRange);
if (count == 0) continue;
create MigrationRequest {
tenantId,
startTime = dayRange.start,
endTime = dayRange.end,
status = "PENDING",
expectedCount = count,
createdAt = currentTimestamp()
}
Tasks were inserted using bulk unordered operations to gracefully handle retries or duplicate task generation attempts. A unique index on {tenantId, startTime, endTime} ensured idempotency, preventing redundant processing if the migration service restarted or multiple instances ran concurrently.
This fine-grained, day-level partitioning allowed robust tracking, clear accountability, and straightforward recovery from any interruptions - critical for executing a high-volume migration safely and effectively.
Parallelism: Multi-Threading and Multi-Pod Execution
Migrating hundreds of thousands of daily data slices across billions of records was no small feat. Achieving this at scale meant embracing parallelism at every layer of our migration service. We deliberately engineered parallelism on two levels - within each service instance and across the entire Kubernetes cluster.
Multi-threading within a Service Instance
Every migration service instance was designed to be a powerhouse of parallel execution. Upon startup, the service would spin up a configurable pool of worker threads - usually around ten, but easily adjustable based on real-world load and environment.
- Tenant-Level Segmentation:
- Each thread was dedicated to a single tenant at any given time. This design decision was deliberate - tenants are naturally isolated, with no cross-tenant dependencies, which allowed us to safely and efficiently run migrations in parallel without risk of contention or corruption.
- Chronological Task Ordering:
- Within each tenant thread, we processed all pending day-range migration tasks one after another, ordered from the oldest to the newest day. While strict chronological order wasn’t technically required, it made troubleshooting, verification, and logging significantly simpler, as the migration’s progress matched a logical and time-ordered flow.
- Practical Benefits:
- This approach not only accelerated throughput but also reduced the risk of task collisions, race conditions, or inconsistent states within an tenant’s data. By keeping each thread focused on a single tenant, we gained clarity in execution and ease in tracing issues.
Multiple Service Instances (Pods) Across the Cluster
Parallelism didn’t stop at the thread level. To further accelerate the migration, we deployed multiple instances (pods) of our migration service across the Kubernetes cluster.
- Uniform Logic Across Pods:
- Each pod independently ran the same multi-threaded model described above. This allowed the cluster to scale horizontally - simply launch more pods to process more tenants simultaneously.
- Conflict Prevention:
- Our task queue in MongoDB enforced a unique index on {tenantId, startTime, endTime} for each MigrationRequest. When multiple pods attempted to pick up the same task, only the first to mark it as STARTED could proceed; all others would immediately recognize it was no longer PENDING and skip it. This guaranteed that every migration task was handled by exactly one thread, in one pod, at any given time - ensuring data integrity and idempotency even during retries or restarts.
- Strategic Tenant Assignment:
- We strategically distributed tenants among pods to maximize throughput and avoid accidental overlap. For particularly large tenants, we sometimes temporarily increased parallelism within a single pod.
Performance Optimization: Finding the Sweet Spot
Achieving optimal throughput was an ongoing process of experimentation and tuning. Here’s how we fine-tuned the migration engine for stability and speed:
- Thread and Pod Sizing: Our initial tests quickly revealed that too few threads left the system underutilized, while too many caused MongoDB overload, network congestion, and sometimes even out-of-memory (OOM) failures. After extensive load testing, we found that about 10 threads per pod consistently provided the best balance, keeping MongoDB, S3, and Kafka pipelines running hot - but never overwhelmed.
- Batch Size Experimentation: Bulk operations were key to throughput. We experimented with batch sizes ranging from 1,000 to 20,000 documents per insert. We ultimately found that 10,000 documents per batch was ideal - small enough to avoid memory spikes, large enough for efficiency across the entire pipeline.
⚠️ Although MongoDB supports bulk inserts up to 100,000 documents per call, our bottlenecks in practice were S3 upload throughput and MongoDB disk IOPS. We occasionally ran into throttling on heavy disk read/write operations, so we tuned batch sizes and thread counts accordingly.
- Dynamic Parallelism: For production clusters with fewer tenants, we scaled parallelism down. When we needed to push harder, we temporarily increased the thread count from 10 to 20 per pod, reducing overall migration time - always watching system metrics to avoid negative impact.
- Iterative Testing: The final configuration was reached only after cycles of measurement and refinement, watching system metrics and error logs, and iteratively dialing in the perfect balance.
Orchestrating the Pipeline
To tie all of this together, our service ran a straightforward but powerful control loop:
// In each service instance:
threadPool = Executors.newFixedThreadPool(NUM_THREADS);
for each tenantId in assignedTenants:
threadPool.submit(() -> migrateTenant(tenantId));
function migrateTenant(tenantId):
tasks = findAll(MigrationRequests where tenantId==..., status=="PENDING", sort by startTime)
for each task in tasks:
processMigrationRequest(task);This enabled, for example, 10 tenants to be migrated in parallel per pod. With N pods running, we could process up to 10×N tenants at once - accelerating the migration.
Streaming Data to S3 for Scalable Storage
One of the most transformative changes in our architecture was offloading large, unstructured data fields (like call transcripts and heavy metadata) from MongoDB to S3.
- S3 Path Strategy: Each document’s payload was uploaded to S3 with a carefully structured key:
- s3://<bucket>/<tenantId>/<YYYY>/<MM>/<DD>/<documentId>_interactions.json
- This not only kept data organized but distributed uploads across many S3 prefixes, maximizing throughput and preventing any single prefix from becoming a bottleneck. (Amazon S3 now supports up to 3,500 PUT/second per prefix.)
- Parallel Uploads: To sustain our target migration throughput, each service instance launched up to 100 parallel S3 upload threads. Leveraging asynchronous programming with tools like Java’s CompletableFuture, we were able to efficiently overlap I/O and CPU operations, maximizing network utilization and upload speed. Because each tenant was mapped to a separate S3 prefix, this design ensured that we distributed requests evenly and stayed well within S3’s per-prefix rate limits. After extensive experimentation, we found that configuring 100 parallel uploads per pod provided the optimal balance between throughput and system stability - enabling us to fully exploit available bandwidth without triggering throttling or RPS bottlenecks.
- Error Handling and Durability: Upload failures - whether due to transient network errors or bad data - were rare, but when they occurred, we logged them for automatic retries. This approach provided durability and minimized manual intervention.
Optimized Bulk Writing to MongoDB v1
With heavy fields moved to S3, the next challenge was to ingest transformed documents into MongoDB v1 efficiently:
- Schema Transformation: Before insertion, we cleaned up each document:
- Removed large, json fields (criteria, signals, parameters), which accounted for the majority of storage bloat.
- Separated comments into their own normalized collection (interactionComments), linking back to the original document.
- Stripped unneeded metadata (like internal _class fields).
- Bulk Insert Strategy: We leveraged MongoDB’s insertMany() operation in unordered mode, enabling the database to parallelize inserts and efficiently skip over any individual document failures without halting the entire batch. Any failed inserts were simply logged for later review. Since our migration process included post-migration verification of record counts for each batch, we could safely tolerate these failures - automatically reprocessing only when discrepancies were detected, rather than interrupting the overall flow.
- Duplicate Handling for Idempotency: In instances where a document has already been migrated (for example, following a retry), MongoDB would trigger a duplicate key error. Our system logged these occurrences and bypassed them, as we did not intend for an already ingested document to be processed again.
- Throughput Maximization:
- Write concern was set to w=1 (no waiting for secondaries), and journaling was disabled for migration operations - trading a small risk window for massive throughput.
- Schema validations were bypassed (bypassDocumentValidation), trusting that source data was already compliant enough for migration.
- Storage and IOPS strategies: We leveraged high-performance NVMe SSDs and carefully provisioned AWS EBS IOPS to ensure our storage layer could consistently support the high write throughput required during migration- up to ~6,000 records per second at peak load.
- Indexing Approach: To optimize for both migration speed and post-migration query performance, we retained only the most essential indexes (such as tenantId and time) during migration. All secondary or complex indexes were created after the bulk load, minimizing write overhead during the critical migration window.
Migration Tracking and Source Cluster Stability
- Non-Intrusive Tracking:To avoid overwhelming the already fragile source cluster (over 9TB and near operational limits), we never marked individual documents there. Instead, we:
- Tracked progress via status updates on the MigrationRequest task queue.
- Verified success using post-insert document counts in MongoDB v1 and S3.
- Handling Live Data: For real-time writes happening during the migration window, we set a lightweight im=true flag on those source records - allowing us to skip redundant migration and avoid duplicate S3 uploads or Kafka republishing.
- Controlled Retries: Once a day-range batch was successfully processed, it was never retried unless explicitly flagged - ensuring efficiency and data integrity.
Integration with Kafka and Snowflake
Migrating the operational database was only part of the goal - we also needed to make 1.8 billion historical interactions available in Snowflake for analytics, and use the migration to load test our pipeline at peak scale. Rather than relying on slow, post-migration bulk imports, we streamed data in real time through our existing Kafka and Snowpipe Streaming pipeline, the same path used for live ETL.
This delivered two key benefits:
- Production-Scale Load Testing: By channeling all migration data through our real-time pipeline, we validated system performance under high-throughput conditions and exposed any bottlenecks early.
- End-to-End Consistency: Using a single ingestion path for both migration and live data ensured MongoDB, Kafka, S3, and Snowflake remained fully synchronized and resilient to duplication or retries.
Kafka Producer During Migration
For each batch of migrated documents, after uploading to S3 but before inserting into MongoDB v1, we published the records to a dedicated Kafka topic (interaction-update).
- Message Format: Each record was serialized as a JSON message, including all relevant fields and the S3 path. The MongoDB _id was mapped to an id field to match downstream schema expectations.
- Asynchronous Publishing: We used a dedicated thread pool - similar in design but smaller than our S3 upload pool - to optimize Kafka publish throughput. With around 50 threads, we found Kafka could easily handle our scale without introducing latency or bottlenecks. Publishing tasks were lightweight and completed quickly, ensuring efficient message delivery without over-provisioning resources.
- Kafka Topic Design: Configured with 10 partitions, the topic could easily handle high parallelism.
- Optimized Throughput: Messages were batched using Kafka producer buffering, fanned out across threads, and monitored for errors and failures in real time.
- Resilience: We sustained a publish rate on par with MongoDB inserts (~6,000+ messages/sec), relying on the idempotency of our Snowflake pipeline to gracefully handle any rare duplicates while ensuring no data loss.
Snowflake Ingestion via Kafka Connector
On the downstream side, we used the Confluent Kafka Snowflake Sink Connector to consume messages from the Kafka topic:
- Scaling Connector Tasks: Starting with 1, we scaled to 5 connector tasks as throughput ramped up. Each task mapped to one or more Kafka partitions for parallel ingestion.
- Reliable Delivery: The connector streamed data via Snowpipe Streaming into a staging table (INTERACTIONS_SYNC_STAGE) while preserving schema mapping and delivery guarantees.
- Dedicated Compute: A separate Snowflake warehouse was assigned to the connector, ensuring that ingestion performance could scale independently and remain isolated from competing workloads.
Deduplication & Merge in Snowflake
To ensure a clean, consolidated analytical view, we built a robust deduplication and merge process:
- CDC Stream: We created a Snowflake stream (INTERACTIONS_SYNC_STREAM) on the staging table to track change data capture (CDC)-style inserts.
- Automated Merging: Every 30 minutes, a scheduled task triggered a JavaScript-based stored procedure (MERGE_INTERACTIONS_SP) which:
- Built a temporary deduplicated table, retaining only the latest version of each record using ROW_NUMBER() OVER (PARTITION BY ID ORDER BY VERSION DESC).
- Merged this deduped data into the final v1 analytics table (OBSERVE_BACKEND_ARCANE_INTERACTIONS) via a Snowflake MERGE statement.
- Idempotent Pipeline: Since our records are immutable post-creation, retries or duplicate messages from the migration or live traffic paths had no impact - thanks to strict _id-based deduplication, re-inserts simply became harmless no-ops.
Observations
By streaming migration data through Kafka:
- We eliminated the need for a massive, separate Snowflake bulk load.
- MongoDB writes and Snowflake ingestion were fully decoupled - each could scale independently.
- Even during peak throughput load, when Snowflake ingestion, especially the dedupe part occasionally lagged behind MongoDB, our ability to quickly scale the warehouse ensured that it always caught up.
- Notably, the Snowpipe Streaming process that appended incoming data to the staging table never exhibited any lag throughout the migration. This highlights just how efficiently Snowflake DW can handle high-volume inserts into a table, whereas deduplication and merge operations are so much more resource-intensive .
In the end, both operational and analytical data stores were fully synchronized—with all 1.8 billion records migrated, deduplicated, and ready for analysis, in near real-time.
Pitfalls and Testing Methodology
We began by validating the migration pipeline in a staging environment using a representative subset of data. For example, we migrated data for a few of our largest tenants—millions of records each—to observe resource utilization and measure throughput. This surfaced critical issues early, such as excessive memory consumption (e.g., out-of-memory errors when processing overly large batches or too many concurrent tasks). We addressed these by tuning batch sizes and adding safeguards for corrupt data. Logging was also optimized, as overly verbose logs became a bottleneck at high throughput.
We encountered two migration requests that failed due to the existing production configuration's size limit, which prevented the interactions from being pushed to the Kafka topic. We increased the size limit and subsequently reran the migration requests.
Incremental dry runs were key to building confidence in our system’s idempotency and resilience. We intentionally interrupted, killed, and restarted the process multiple times to verify that it would reliably resume without duplicating or skipping data. As a result of this iterative testing, we steadily improved performance - reaching 3k/sec, then 5k/sec, before launching the full-scale production migration.
By the time we went live, we were sustaining 5,500–6,000 records per second (about 500 million records per day). Throughput varied slightly - slower for exceptionally large tenants or during heavy disk I/O - but consistently met our targets. The entire backfill of 1.8 billion records was completed in just four days. Throughout, the legacy system stayed online, with all reads performed on secondaries (secondaryPreferred) to avoid impacting live traffic. Both v0 and v1 continued to accept writes, ensuring operational continuity.
Results, Learnings, and Future Considerations
The migration wrapped up successfully, moving all 1.8 billion documents to the new stack. Post-migration verification was an essential phase: for every tenant, we compared the record counts in v0 and v1 to ensure completeness. In addition to these count checks, we ran spot audits across random days and tenants - comparing sample documents, verifying S3 object existence, and cross-checking that the data was consistent between all stores. Thanks to detailed logging and the status fields in our MigrationRequest records, any discrepancies stood out clearly and were easy to investigate.
In practice, we found just a handful of minor mismatches. Typically, a day-range would be marked “MISMATCH” if the count in v1 differed from v0 by one or two. Upon investigation, these cases always traced back to records that were legitimately updated or deleted in v0 by other processes during the migration window. Since the migration was essentially a snapshot at a point in time, such minor differences were expected and easily reconciled manually. The net error rate was vanishingly small - on the order of 0.0001%. Most importantly, there was zero data loss: our combination of idempotent bulk writes and thorough post-migration verification ensured completeness and consistency across all stores.
System Impact
Despite the scale, production impact was minimal. Our throttling strategy ensured the v0 cluster could handle migration reads without affecting live traffic. The new v1 cluster—since it wasn’t yet serving production - absorbed the write load easily.
The Kafka/Snowflake pipeline kept up smoothly, and once the backfill finished, analytics teams could access all the migrated data in Snowflake right away.
That said, as writes ramped up on v1, we did notice some write delays and a few latency alerts. We acknowledged these, and this was when we decided to upgrade our MongoDB cluster to NVMe storage, which resolved the issue.
Key Learnings from the Migration
Granular Partitioning Makes Big Jobs Manageable
Breaking the migration down into tenant-by-day tasks made an enormous project tractable. Fine-grained units allowed us to parallelize aggressively, track progress precisely, and reprocess small slices when issues came up—instead of re-running the entire migration.
Idempotency and Recovery are Non-Negotiable
Failures, restarts, and edge cases are inevitable at this scale. By designing every migration step to be idempotent (safe to retry, tolerant of duplicates), and by tracking progress at each stage, we ensured that the migration could always resume cleanly after any interruption.
Real-Time Pipelines Enable Live Validation and Faster Cutover
Streaming historical data through the same pipeline used for live ETL meant we could validate our architecture under realistic, production-like loads. This gave us immediate feedback on bottlenecks, uncovered scaling issues early, and meant there was no separate “bulk load” step needed for analytics. As soon as migration finished, the live cutover was seamless.
Infrastructure Should Scale With the Migration, Not After
Performance bottlenecks often showed up as the migration scaled up (especially with storage and IOPS). Proactive monitoring and rapid infra upgrades—like switching to NVMe disks—helped us maintain target throughput and avoid prolonged slowdowns. Planning for these upgrades ahead of time can prevent surprises.
Communication Across Teams is Critical
Migrating data at this scale impacts many stakeholders—from ops and engineering to analytics and product. Regular status updates, transparent dashboards, and clear cutover plans ensured everyone was aligned, reducing the risk of confusion or last-minute surprises.
Incremental Testing Prevents Costly Surprises
Running the migration end-to-end on smaller subsets of data and staging clusters surfaced issues like memory usage, logging verbosity, and recovery bugs early. These dry runs gave us confidence before we ran the full migration in production.
Data Validation Must Be Layered
Basic record counts alone aren’t enough at this volume. We layered on random sampling, schema checks, S3 object verification, and checksum comparisons to ensure both completeness and data integrity. This allowed us to deprecate the old system with confidence.
Scale is a Moving Target - Balance is Key
It was tempting to throw more pods or threads at the job, but unbalanced scaling quickly led to IOPS limits, replication lag, or Kafka backpressure. We learned to observe system metrics closely and fine-tune concurrency for stable, predictable performance.
Looking Forward
With all historical data now migrated, our production pipeline seamlessly writes into MongoDB v1, offloads heavy content to S3, and streams updates into Snowflake using the same architecture we validated under peak migration loads. This design is not only more scalable and analytics-friendly, but now thoroughly battle-tested for future growth.
Future Opportunities and Improvements
- Automation and Self-Tuning:
During this migration, we manually adjusted thread pools and pod counts to balance throughput and stability. In future migrations, we envision adding a controller or feedback loop to automatically scale pods and threads based on real-time metrics - allowing the pipeline to self-tune and react dynamically to system load or bottlenecks.
- Enhanced Data Quality Checks:
Beyond count comparisons and sampling, we plan to incorporate hash or checksum-based validation per batch or day, on both source and target. This would catch even subtle data drift or corruption at scale, without the overhead of field-by-field comparisons.
- Alternative Ingestion Strategies:
Kafka fit naturally into our architecture for streaming to Snowflake, but in some scenarios, direct Snowpipe REST or Bulk API integration could reduce latency and operational complexity. The trade-off: Kafka provides a robust buffer and monitoring, whereas direct loads may be harder to observe in-flight.
- Distributed Computing Engines for Future Scale:
While our current approach achieved excellent results with custom multi-threading and Kubernetes orchestration, we recognize that distributed computing engines like Apache Spark or Apache Flink could offer significant advantages for even larger-scale migrations.
In Closing
Migrating billions of records is never easy—you’re guaranteed to hit system and process limits somewhere along the way. But with the right strategy, observability, and engineering discipline, you can deliver a safe, high-performance migration with minimal business disruption. Our architecture (MongoDB v1 + S3 + Snowflake) is already yielding dividends: faster queries, leaner storage, and easier scaling for analytics. We hope the lessons and approaches outlined here—like day-wise partitioning, async I/O, and automated validation—help others navigating their own big-data migration journeys. Happy migrating!
Subscribe to our newsletter.
Frequently Answered Questions

.png)



.png)
.png)