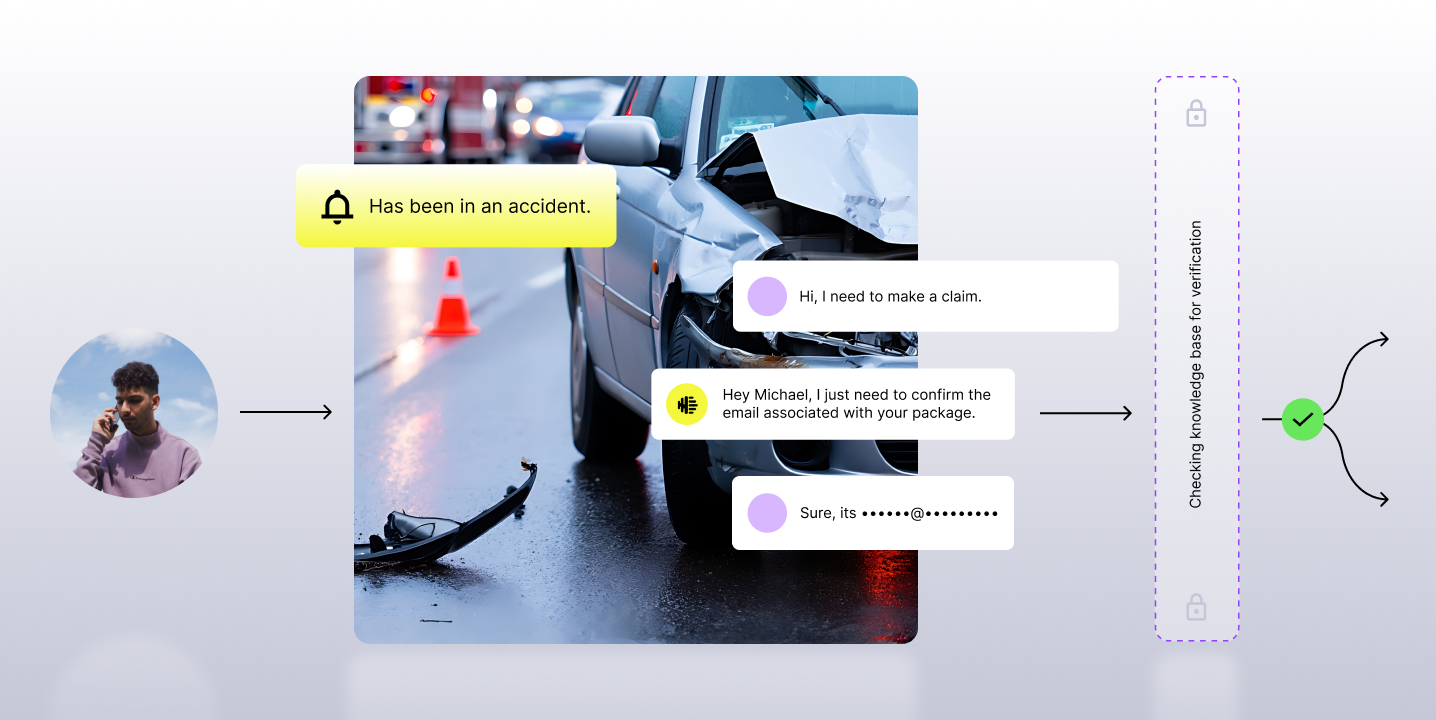
It’s Not the Model. It’s the Pipeline: What Really Happens When an AI Agent Answers the Phone
Most people think of voice AI in terms of the model. The LLM, which provides the intelligence, is the part that generates a natural-sounding response. But if you’re responsible for putting AI agents into production, you already know the truth: the model is only a fraction of the system.
A successful AI agent starts long before the LLM begins to “think,” and it involves a chain of engineering decisions that determine whether the experience feels seamless or immediately falls apart.
In this blog, our team walks through the entire journey of a single customer utterance, from noisy audio coming off a phone line to the crisp, generated voice that responds a fraction of a second later. This walkthrough underscored something every enterprise adopting voice AI needs to understand:
The intelligence of the AI matters.
But the pipeline's reliability matters more.
This blog opens that black box and explains, in plain language, what actually happens inside a modern Voice AI system, and why those engineering layers determine real-world outcomes more than any benchmark you see in a model card.
It Starts With the Messiness of the Real World
When a customer speaks, they’re not doing it from a soundproof booth. They’re sitting in a car with road noise, or in a kitchen with the TV on, or in an office with someone talking behind them. Only rarely does a customer seek support in a sterile, audio-perfect environment, and if you feed that raw audio that includes real-world background noise directly into a speech model, the AI is already in trouble.
That’s why everything begins with signal hygiene.
Before intelligence, there’s clarity.
We run a proprietary machine learning-based (ML-based) noise filter, that doesn’t just remove static or hum, but specifically targets background speech, the type of noise most likely to derail a voice AI system. Background voices tend to be low-volume, broken, and intermittent, but still structured enough to confuse a model. By filtering out those patterns, the AI agent hears only the person it’s speaking to, not the room around them.
Most vendors never talk about this step. But you’ll notice it immediately when calls fail.
Knowing When Someone Is Talking Is Half the Battle
After the audio is cleaned, the system still needs to understand when the customer is actually speaking. This is where Voice Activity Detection (VAD) comes in. VAD separates speech from silence, breathing, clicks, and other non-verbal noise. It’s what prevents your AI agent from interrupting the caller, or from waiting too long to respond.
Latency at this stage is measured in milliseconds and determines whether a human perceives the agent as following the rhythm of a real conversation. The right balance of understanding when a customer is speaking and when the AI agent should jump in is a delicate dance, while managing the latency of multiple tools, including the noise filtering, LLM, and response generation.
If this layer is sloppy, the entire interaction feels clunky, robotic, and wrong, no matter how good the LLM is.
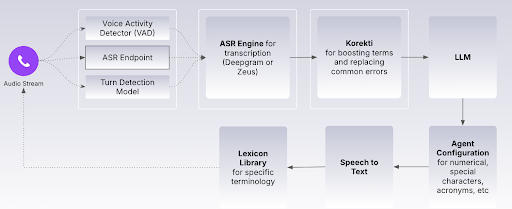
Transcription: The First Place Accuracy Can Break
Only after noise is removed and speech segments are identified does the system attempt to understand what was said. This is the ASR (Automatic Speech Recognition) stage.
We support multiple ASR models, including our own Observe.AI purpose-built model, because different enterprises have different accuracy, compliance, and deployment needs. Some want cloud-based models. Some require a fully self-hosted option for PCI or data residency requirements. Either way, the transcription becomes the input to everything that follows.
And here’s the uncomfortable truth for anyone deploying AI agents:
If the transcript is wrong, the LLM will be wrong. There is no magic prompt that fixes a flawed foundation.

This is why we built advanced speech-to-text (STT) controls on top of the ASR. They allow teams to boost or make important words (brand names, domain terms) deterministic, and suppress others (profanity, irrelevant background words). With newer models, boosting becomes more implicit (keyword prompting replaces numerical weights) but the principle remains: enterprises need control over vocabulary sensitivity.
These aren’t “nice to have” tweaks. They are survival tools for accuracy in high-stakes conversations.
Correcting the Transcript Without Repeating the Call
Even after careful setup, every ASR system has known failure cases: names it struggles with, product terms it mishears, and regional pronunciations that bend the rules. To that end, we maintain a post-processing layer that corrects transcripts before they reach the LLM.
It’s not magic. It doesn’t guarantee a perfect correction every time. But it significantly reduces preventable misinterpretations, especially in industries where a single vowel can change the meaning of a policy, medication, or account identifier.
Every accuracy win here compounds downstream.
This Is Where the LLM Finally Enters the Conversation
Only after all of that: the cleaning, the segmentation, the transcription, the correction—does the text reach the LLM, which generates the next action or response. This is the part people like to talk about. The part that feels futuristic. And yes, this is where the “intelligence” comes into play: determining intent, applying task logic, calling tools, and producing the right answer.
But the effectiveness of the LLM is only as strong as the pipeline that feeds it.
It can’t reason with words it has never heard correctly.
It can’t respond naturally if interruptions aren't handled cleanly.
It can’t make decisions confidently if the noise distorts customer intent.

Giving the AI a Voice That Sounds Human Without Losing Control
Once the LLM produces its response, the system converts text back into speech. This is the Text-to-Speech (TTS) stage, and it is more nuanced than most people realize.
Different providers (Elevenlabs, Deepgram, AWS Polly, Google) offer different tradeoffs: realism vs. stability, expressiveness vs. predictability, speed vs. naturalness. We give teams the ability to tune these parameters so the AI sounds like their brand, not a generic robot.
Too much variation and the voice drifts unpredictably.
Too little and it becomes robotic.
Finding the right balance is part engineering, part brand identity.
We even allow phonetic overrides for specific words the model struggles to pronounce. It’s a level of polish that only matters once you’ve solved the fundamentals. And it makes all the difference for customer trust.
Interruptions Are Human. Your AI Must Handle Them.
Real conversations aren’t linear. People interrupt. They correct themselves. They say “Hold on” or “Wait, actually” in the middle of the bot’s sentence.
If your AI agent can’t gracefully yield, it breaks the illusion of natural conversation instantly. Or, worse, it starts a chain reaction of interruptions and confusion for both the caller and the AI agent.
We insert an interruption processor that detects when the customer begins speaking and decides how quickly the bot should stop. Some utterances should interrupt immediately (“Stop”, “Wait”). Others should allow the agent to complete a mandatory phrase (e.g., compliance disclosures, account disclaimers).
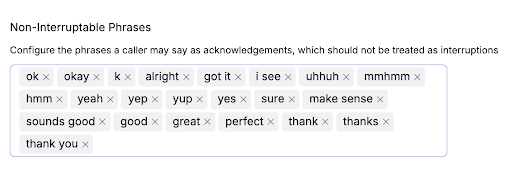
This is one of the hardest parts of making voice AI feel “alive” and one of the least appreciated.
Protecting Sensitive Data Without Breaking Analytics
Finally, once the call ends, we apply PII redaction to the transcript and delete audio recordings for customers who require that level of protection. But we still preserve operational metrics, such as timing, tool usage, region, events, so that evaluations, reporting, and audits remain intact.
You remove sensitive data.
You keep the insights that matter.
That’s what responsible AI operations look like.
Why OOTB Won’t Cut It
None of the complexity above is visible to the customer. They hear a friendly voice and assume the system “just works.” But for CIOs and IT leaders, this architecture is the difference between:
An AI agent you can trust in production and A bot that collapses the second it meets the real world.
Every stage, noise filtering, VAD, ASR, transcript corrections, LLM orchestration, TTS, interruptions, redaction, contributes to reliability, latency, compliance, and brand experience. If a single layer underperforms, the entire interaction suffers.
This is why enterprises can’t evaluate voice AI on demos alone.
You evaluate it on infrastructure.
On the maturity of the pipeline.
On how it handles the messy reality of customer conversations.
Voice AI is not a model.
It is a system.
And systems succeed or fail long before the “intelligence” comes into play.
DIY gets you a prototype. We get you to production.
If you’re ready for an AI agent that can earn trust at enterprise scale, we’re ready when you are.
Subscribe to our newsletter.
Frequently Answered Questions